Zapowiadany tekst miał wyłącznie dotyczyć złożoności nieredukowalnej ale ostatnie komentarze pod poprzednim wpisem https://ekspedyt.org/2025/11/25/inteligentny-projekt-ip-zwany-bozym-planem/ spowodowały, że trochę obszerniej potraktuję temat projektu i złożoności nieredukowalnej.
Proca:
„(…) Jeżeli projekt IP jest wyłącznie wytworem biologiczno-matematyczno-logiczno-teologicznym, więc w sumie metodologicznie jest przekroczeniem kompetencji, tzn. łączenie w jedno różnych dziedzin wiedzy daje niestrawną mieszankę. (…)”.Piko:
„Pan myli dwie sprawy – metody badawcze (dobre, złe, bez sensu) i teorię IP, która nie jest metodą badawczą, jest reakcją na TE, która używając “demona przypadku” twierdzi, że życie powstało samoistnie z “bulionu” a potem na drodze przypadkowych mutacji i doboru ewoluowało w Kowalskiego”.Proca:
„Chyba nie mylę dwóch spraw; każda teoria, nawet teoria IP musi używać jakiejś metody, by zweryfikować swoje hipotezy, w przeciwnym wypadku nie można tego nazwać ‘teorią`”.
Tak IP używa takich narzędzi/metod jak: logika, wiedza o procesach i budowie struktur biologicznych, fizyka, biochemia, rachunek prawdopodobieństwa, cybernetyka, teoria sygnałów. Nie ma w badaniach żadnych teologicznych podpórek. Teologiczne są jedynie wnioski wynikające ze stanu obecnej wiedzy.
Biologia i medycyna są obszarami interdyscyplinarnymi więc twierdzenie: „łączenie w jedno różnych dziedzin wiedzy daje niestrawną mieszankę” jest fałszem, a logiką zawsze trzeba się posługiwać.
A teraz do meritum.
Niedarwinistyczny biolog, Stuart Kauffman stwierdził:
„Ktokolwiek, kto powie ci, że wie jak jakieś 3,45 miliardów lat temu na Ziemi powstało życie to głupiec lub szelma. Nikt tego nie wie. Co więcej, być może nigdy nie będziemy w stanie odtworzyć faktycznej historycznej sekwencji molekularnych zdarzeń, które doprowadziły do pierwszego samoreplikującego się, ewoluującego molekularnego systemu, który zakwitł ponad 3 miliony milenniów temu. Ale nawet jeśli ta historyczna ścieżka pozostanie już na zawsze ukryta, wciąż możemy rozwijać szereg teorii i eksperymentów ukazujących, jak życie mogło realistycznie uformować, zakorzenić i rozprzestrzenić się na cały świat”.
Z kolei Leslie Orgel napisał:
“Ktokolwiek, kto sądzi, że zna rozwiązanie problemu powstania życia oszukuje się. Ale, ktokolwiek sądzi, że jest to problem nierozwiązywalny także oszukuje się. Możliwe podejście do problemu powstania życia to zadanie pytania naukowego niż historycznego – jak życie może powstawać niż jak powstało. Aby odpowiedzieć na to pytanie, naukowcy próbują eksperymentalnie określić, co jest chemicznie możliwe i co mogło wydarzyć się na prebiotycznej Ziemi“.
Zastrzeżenia Kauffmana i Orgela stają się jaśniejsze, jeśli uświadomimy sobie co powinno być wyjaśnione: mianowicie naturalistyczne powstanie komórki z jej całą zdumiewającą złożonością. “Takie sobie bajeczki”, jak życie mogło powstać w wyniku długotrwałego mieszania się składników na prebiotycznej Ziemi nie mają ani eksperymentalnego poparcia ani teoretycznych fundamentów [patrz poprzednie teksty]. Co istotniejsze, im więcej i więcej wiemy o biochemicznych podstawach i złożoności życia, tym naturalistyczne opowiastki o spontanicznej abiogenezie wydają się być mniej i mniej prawdopodobne.
Naturalistyczne ujęcia spontanicznego powstania życia załamują się na dwóch zasadniczych poziomach: inżynierii systemowej i symbolicznego zapisu i przetwarzania informacji.
Inżynieria systemowa
Bruce Alberts, prezydent amerykańskiej National Academy of Sciences charakteryzując komórki stwierdził:
“Długo nie docenialiśmy komórek. […] Cała komórka może być przedstawiona jako fabryka zawierającą skomplikowaną sieć połączonych linii montażowych, każda z nich złożona z układu dużych białkowych maszyn. […] Dlaczego możemy nazywać duże białka montażowe tkwiące u podstaw komórkowych funkcji maszynami? Ponieważ dokładnie tak, jak maszyny wynalezione przez ludzi do efektywnego działania w makroskopowym świecie, te montażowe białka zawierają precyzyjnie zintegrowane ruchome części”.
W grudniu 2003 r., fachowy periodyk, BioEssays, opublikował własne wydanie dotyczące “molekularnych maszyn”. We wprowadzeniu do niego Adam Wilkins, redaktor BioEssays wyjaśnia:
“Artykuły w tym wydaniu ukazują niektóre pewne uderzające podobieństwa pomiędzy sztucznymi a biologicznymi/molekularnymi maszynami. Przede wszystkim molekularne maszyny, tak jak maszyny robione przez człowieka, wykonują dokładnie określone funkcje. Po drugie, makromolekularne maszyny składają się z wielu części, oddziałujących ze sobą w odrębny i precyzyjny sposób. Po trzecie, wiele z tych maszyn posiada części, które mogą być użyte w innych molekularnych maszynach (przynajmniej z niewielkimi modyfikacjami), co jest porównywalne z wymienialnymi częściami w sztucznych maszynach. W końcu, co najważniejsze, posiadają one podstawową cechę maszyn: zamieniają energię w jakąś formę ‘pracy’“.
Biologia głównego nurtu nie ma problemów z przyznaniem, że komórki to wyrafinowane nanotechnologiczne maszyny i systemy. Zgodnie z inżynieryjnym rozumieniem, systemem jest: „Zbiór lub aranżacja powiązanych ze sobą elementów i procesów, których zachowanie spełnia operacyjne potrzeby produktu, podtrzymując jego życiowy cykl”.
Aby system funkcjonował musi posiadać:
- strukturę definiowaną przez jego komponenty i ich wzajemne relacje
- zachowanie/działanie: dane wejściowe, przetwarzanie tych danych i dane na wyjściu w postaci materiału, energii lub informacji
- zdolność komunikowania się ze sobą jego komponentów: różne części systemu posiadają zarówno funkcjonalne, jak i strukturalne relacje z innymi częściami tegoż systemu.
Nawet najprostsza komórka to z punktu widzenia nanotechnologii i inżynierii systemowej elegancki i wyrafinowany majstersztyk. W komórce znajdziesz:
- Przetwarzanie, zapisywanie i odczyt informacji
- Symboliczne kodowanie informacji z jej własnym systemem kodującym/dekodującym
- Kod korekcyjny i urządzenia kontroli jakości
- Elegancki system sprzężeń zwrotnych (dodatnich i ujemnych) monitorujących i regulujących komórkowe procesy
- Technologie wbudowanych danych
- Wyrafinowane przetwarzanie sygnałów
- Systemy transportujące i dystrybucyjne
- Zautomatyzowany system adresowania
- Bazujące na technologii modułów i prefabrykatów procesy produkcyjne
- Zrobotyzowane, samoreplikujące się nanofabryki.
Tylko inteligencja jest w stanie generować tego typu układy. Nie znamy żadnych praw natury, które preferowałyby spontaniczne tworzenie się tego typu systemów.
Przykłady inżynierii systemowej czyli maszyny molekularne: wić bakteryjna, białka motoryczne, rybosomy odpowiedzialne za transkrypcję, niszczarki proteasomy. W zasadzie cała komórka jest maszyną molekularną o nieredukowalnej złożoności.
Żeby tekst nie był zbyt obszerny przedstawię tylko jak jest skonstruowana wić bakteryjna.
W naszych jelitach żyje bakteria pałeczka okrężnicy (Escherichia coli). Normalnie jest pożyteczna, rozkłada niektóre białka do stanu w którym mogą być wchłonięte przez kosmki jelitowe, a przy okazji sama się pożywia. Dla uzmysłowienia skali w jakiej się poruszamy wymiary tego stworka – ma kształt walca o długości 2-3 μm i średnicy 1 μm (1μm = 1/1000 mm, grubość włosa = 1/10 mm).
Niektóre szczepy mają wici służące do poruszania się. Długość wici jest 8-10 razy dłuższa od samej bakterii. Wici umożliwiają przemieszczanie się w kierunku pożywienia wykrytego przez receptory, ewentualnie oddalanie się od substancji szkodliwych.
Bakteria może się przemieszczać w ciągu sekundy na odległość równą jej 35 długości (bez wici). Przeliczając to na nasze realia to jakby podwodna motorówka poruszała się z prędkością ok. 200 km/godz (nie w wodzie a w kisielu). Kierunek ruchu może być zmieniany o 60-90 stopni. Może też poruszać się wstecz.
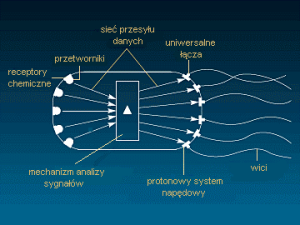
Układ napędowy składa się z trzech elementów
- rotacyjnego silnika protonowego w ilości od 4 do 6 sztuk o odwracalnym ciągu, osadzonego w ścianie komórkowej (jego wewnętrzna część umieszczona jest w cytoplazmie, zewnętrzna w zewnętrznej błonie komórkowej);
- krótkiego haczyka (kątnika), który pełni funkcję elastycznego łącza;
- długiej spiralnej wici.
Dodatkowo mamy jeszcze chemoreceptory, prędkościomierz i skrzynie biegów umożliwiającą różne rodzaje pracy silnika.
Poniżej „schemat blokowy” bakterii.
Wygląd silnika protonowego bakterii.

Koncepcyjny schemat bakteryjnego silnika protonowego E. coli z oznaczeniem białkowych kompleksów składających się na ten układ.
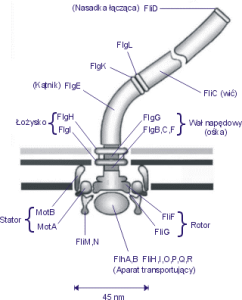
Aparat transportujący to specjalne urządzenie regulujące dopływ poszczególnych podzespołów koniecznych do zmontowania silnika i wici. Proszę zwrócić uwagę na wymiar silnika – średnica ok. 45 nm. Dla przypomnienie – skok jednego zwoju DNA 3,4 nm. Ścieżka w procesorze starszej generacji 32 nm.
Istnieją trzy modele opisujące działanie silnika – obraca się na zasadzie „turbiny wodnej”, „kołowrotka”, silnika elektrycznego. Najbardziej popularny jest model elektrostatyczny.
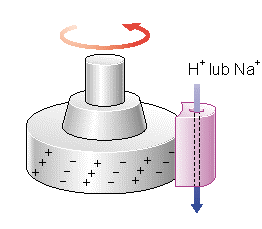
Obrót rotora powstaje w wyniku elektrostatycznego oddziaływania pomiędzy strumieniem protonów lub jonów sodu przepływających przez tunel w białku statora MotA i MotB a ładunkami na powierzchni białka rotora FliG.
Silnik napędowy może obracać się z prędkością 1000 – 1500 obr/sek. Potrafi niezwykle szybko (w ciągu ćwiartki obrotu) zmienić kierunek rotacji.
Zamieszczony film najlepiej uzmysłowi z czym mamy do czynienia.
Kilka dodatkowych niezwykłości:
- Cała bakteria powstaje w ciągu 20 minut, to znaczy jedna dzieli się na dwie w pełni funkcjonalne
- Nić DNA E. coli ma długość 700x większą niż długość ciała bakterii. Około 50 różnych białek bierze udział w zmontowania układu napędowego i nawigacyjnego bakterii. Jak sprawne są mechanizmy biologiczne, że tak długa nić DNA pomieściła się w bakterii oraz jak szybko jest wyszukiwana informacja niezbędna do syntetyzowania białek, która jest przecież rozrzucona w różnych miejscach helisy.
- Najmniejszy błąd w odczycie kodu uniemożliwia poprawną konstrukcję silnika
- Bakteria dokonuje napraw „w biegu” części statycznych.
- Potrafi wymieniać ruchome części silnika w ciągu 20-30 sekund w czasie pracy. Jest to proces dynamiczny, automatyczny, reagujący na sygnały z środowiska. Wyobraźmy sobie wymianę części łopatek w pracującym silniku turboodrzutowym.
Jakie wnioski z tego odkrycia?
Silnik protonowy E. coli do złożenia i funkcjonowania potrzebuje około 30-40 precyzyjnie zintegrowanych białek oraz dodatkowych 20 asystujących przy jego budowaniu. Brak któregokolwiek białka wchodzącego w skład silnika, uniemożliwia zmontowanie sprawnego systemu lokomocji.
Oznacza to, że nieredukowalna złożoność bakteryjnego silnika protonowego jest empirycznie potwierdzonym faktem i system ten doskonale spełnia kryteria oryginalnej definicji nieredukowalnej złożoności zaproponowanej przez Behe’ego:
„System nieredukowalnie złożony to pojedynczy system składający się z wielu precyzyjnie zintegrowanych i oddziałujących ze sobą podzespołów, tworzących podstawową funkcję systemu, w którym usunięcie jakiegokolwiek z tych podzespołów skutkuje faktycznym załamaniem się funkcjonowania takiego systemu.”
Teoria ewolucji w żaden sposób nie jest w stanie wyjaśnić jak takie urządzenie mogło powstać. Nie ma możliwości aby przypadkowo pojawiające się zmiany mogły się przekazać, bo nie ma powodu dla ich istnienia na poszczególnych etapach selekcji. Funkcjonalność pojawia się tylko jeżeli mamy 100% kompletność. „Ewolucja” przecież nie wie do czego dąży, na każdym drobnym etapie weryfikuje przez selekcję czy przypadkowe rozwiązanie jest pozytywne czy nie, czy czemuś służy. Tu tylko kompletny układu wykazuje swoją funkcjonalność.Więcej szczegółów na temat wici i złożoności nieredukowalnej w PDF do pobrania pod tym linkiem:
Innymi przykładami złożoności nieredukowalnej jest kaskada krzepnięcia krwi i proces widzenia. Na życzenie do omówienia w osobnym tekście.
Symboliczny zapis i przetwarzanie informacji
Biologiczne systemy w procesach życiowych używają symbolicznego zapisu i przetwarzania informacji, np. system DNA –> RNA –> białka, gdzie symboliczna informacja – plan budowy pierwszorzędowej struktury białek zakodowana w łańcuchu kwasu deoksyrybonukleidowego (DNA) jest czytana, interpretowana i wykonywana przez komórkową maszynerię, co przekłada się na powstanie finalnego produktu – białek.
Ze swej natury, symboliczna informacja jest zewnętrzna w stosunku do swego nośnika. Co więcej, ta sama informacja może być przenoszona przez bardzo różne nośniki (radiowo, elektrycznie, światłowodem) i systemy kodowania, jak np. binarny czy analogowy. Znaczenie symbolicznej informacji pochodzi zaś z pewnej konwencji, systemu interpretacyjnego, który definiuje system mapowania symboli na ich znaczenie.
Dlaczego kodon (trójka nukleotydów) AUG koduje symboliczną informację oznaczającą aminokwas metioninę, a nie dajmy na to glicynę? Z podstawowych praw fizyki i chemii nie wynika nic, co by determinowało takie właśnie znaczenie tego kodonu, które nadawane jest przez komórkową maszynerię przetwarzającą tę informację. Podobnie, jak prawa te nie determinują, że napisane na kartce słowo ZAMEK ma takie czy inne znaczenie. W istocie – podobnie, jak w naszym języku, gdzie te same słowa mogą przenosić różne znaczenia – kodon AUG może kodować także sygnał START.
Proponuję wrócić do pierwszego tekstu https://ekspedyt.org/2025/10/19/informacja-instrukcja-projekt-biologia/ gdzie podałem konkretny przykład kodowania. Fragment:
… proszę sobie uświadomić, że zakodowana informacja opisana ciągami literowymi np. ACG, GUC, CAU, … (kodowanie aminokwasów do budowy białek) przenoszona jest przez złożone cząsteczki chemiczne, ale nie jest przez nie definiowana. Wzajemny układ tych cząsteczek, kod, reguła, sekwencja stanowi informację, która nie jest tożsama z materią czy energią.
DNA jest „falą nośną” nie informacją. Można sobie nawet wyobrazić, że inne związki chemiczne są używane do kodowania, co można by porównać do przejścia na inny alfabet np. z łacińskiego na cyrylicę – sens, przekaz dzieła literackiego nie zależy od alfabetu w którym go napisano.
Po prostu trzeba sobie uzmysłowić, że informacja, czyli ustanowienie reguł, języka, kodu była od początku.
Podobną sytuację można zaobserwować w naszej technologii. Analogia z techniką cyfrową może być pomocna. Załóżmy, że masz ciąg sygnałów elektrycznych lub świetlnych i luk pomiędzy nimi. Sygnał reprezentujesz jako 1, jego brak jako 0. Przykładowo mamy taki ciąg:
01000001
Co znaczy ta sekwencja? Otóż znaczyć może wiele różnych rzeczy, zależy jak oprogramowanie interpretuje taki ciąg sygnałów. Może to znaczyć literę „A” w kodzie ASCII, ale może to też znaczyć liczbę 65. Może to być nagłówek pakietu transmisyjnego lub wskaźnik do komórki w pamięci komputera, może to znaczyć wiele innych rzeczy. Sama fizyczna natura impulsów nie determinuje ich znaczenia, ono jest dopiero nadawane przez odpowiednie oprogramowanie.
Tekst który czytacie coś znaczy nie dzięki fizyce impulsów komputerowych i grafice na ekranie tylko dzięki informacji stowarzyszonej z jakimś systemem kodowania/rozumienia/wiedzy.
Powstanie na prebiotycznej Ziemi symbolicznej informacji to z punktu widzenia naturalistycznych, niekierowanych inteligencją procesów sprawa beznadziejna – one po prostu nie generują niczego takiego. Inteligencja to jedyne znane nam źródło zdolne do generowania kodów i związanej z nimi symbolicznego zapisu informacji.
Współczesna biologia zaczyna rozpoznawać kluczowe znaczenie informacji w zrozumieniu życia. Noblista i dyrektor Caltech, David Baltimore, opisując znacznie Human Genome Project, stwierdził :
“Współczesna biologia to nauka o informacji”.
W zaczarowanym świecie ewolucji kody piszą się same, ich systemy interpretacji powstają same a wyrafinowana maszyneria mapująca symboliczny zapis informacji na finalny produkt tworzy się sama w wyniku kumulowania się błędów. Niestety (albo na szczęście), kraina ta istnieje tylko w ewolucyjnej wyobraźni.
Dodaj komentarz